
I’m trawling through conventional theory at the moment to see if my approach shows up on the radar anywhere – if it does then I can probably get some hints and tips on what could make it better or if I am doing something wrong.
This is the second of three posts.
Conventional wisdom is that you perform the following steps.
-
Write down the regular language for the input grammar.
-
Build an NFA (non-deterministic finite state automata).
-
Convert the NFA into a DFA (deterministic finite state automata).
-
Systematically shrink the DFA.
-
Turn it into code or a lookup table.
Step 1) Write Down The Regular Language
( a | b )* abb
Step 2) Build An NFA (Using Thompson’s Construction aka Inductive Construction)
For a Given Regular language, Building the NFA is generally done using Thompson’s construction.
First parse a regular language into constituent subexpressions.
eg. for ( a | b )* abb you would produce the following expression tree…
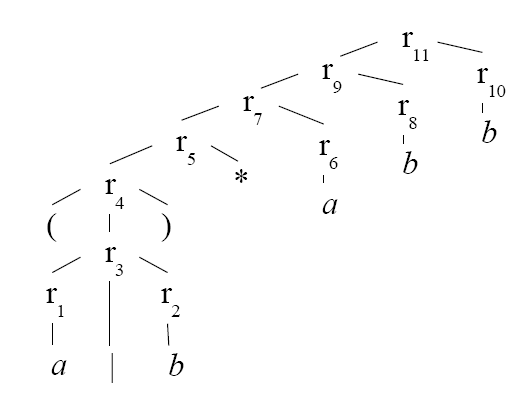
Now traverse the tree depth first and construct the NFA using the following rules.
a) For e (no input) construct the following pattern

b) For a single character, ‘a’ construct the following pattern.

Now we get into the rules for compositing TFA’s together with the various logical operations.
c) For constructing a composite NFA from two pre-existing NFAs s and t in the form of (s | t) . Let NFA(s) and NFA(t) be the NFAs for regular expressions s and t. Construct the following pattern.
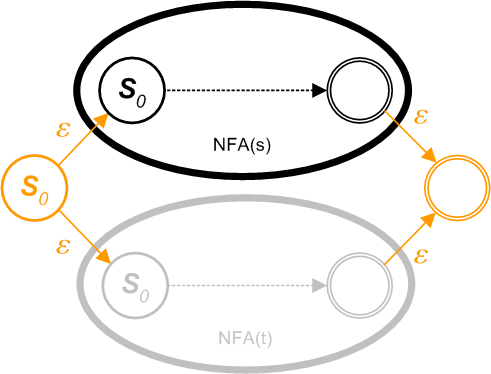
s|t
Newly added nodes are in orange.
d) For constructing a composite NFA from two pre-existing NFAs s and t in the form of st . Let NFA(s) and NFA(t) be the NFAs for regular expressions s and t. Construct the following pattern.

st
Merge final state of NFA(s) and initial state of NFA(t) (in orange)
e) For constructing an NFA in the patten of a Kleene Star (a sequence of zero or more elements) from an existing NFAs s in the form of s* . Let NFA(s) be the NFA for the regular expressions s. Construct the following pattern.
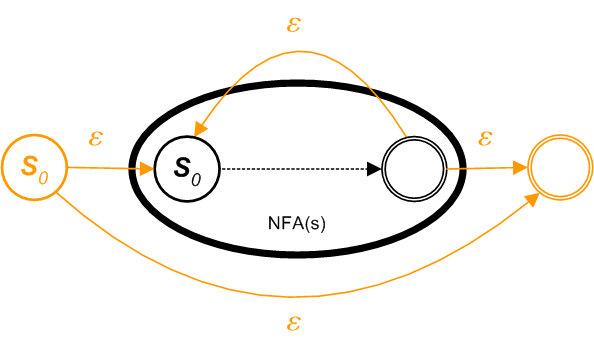
s*
Newly added nodes are in orange.
f) For constructing an NFA in the patten of a Kleene Cross (a sequence of at least one element) from an existing NFAs s in the form of s+ . Let NFA(s) be the NFA for the regular expressions s. Construct the following pattern.

s+
Newly added nodes are in orange.
g) For constructing an NFA in the patten of an option (zero or one element) from an existing NFAs s in the form of s? . Let NFA(s) be the NFA for the regular expressions s. Construct the following pattern.
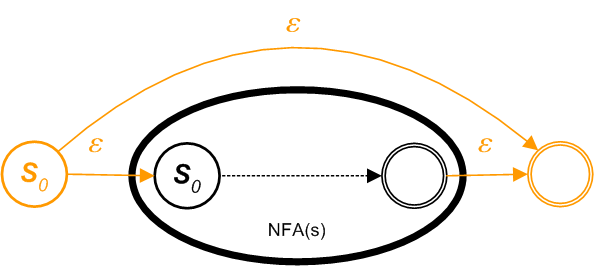
s?
Newly added nodes are in orange.
Our example language of ( a | b ) * abb would parse as
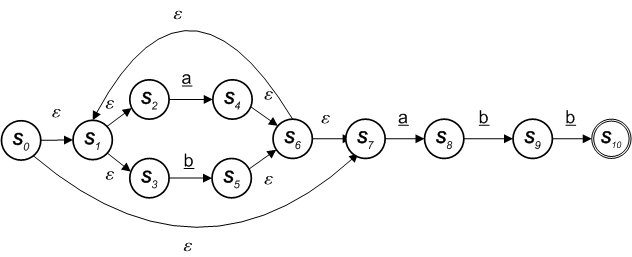
( a | b ) * abb
However the following is what you get if a human designs it.

A more dramatic example of the inefficiency is the NFA generated for a ( b | c ) * would look like
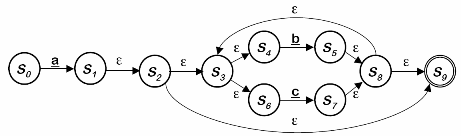
a ( b | c ) *
Generated by Thompson’s Method
However the following is what you get if a human designs it.

a ( b | c ) *
Generated by Common Sense
But its good to know we can automate the generation – even if the result is not optimal.
Step 3) Convert the NFA into a DFA (Determinisation)
A Commonly used algorithm – subset construction.
From the point of view of the input, any two states that are connected by an e-transition may as well be the same, since we can move from one to the other without consuming any character. Thus states which are connected by an e-transition will be represented by the same states in the DFA.
If it is possible to have multiple transitions based on the same symbol, then we can regard a transition on a symbol as moving from a state to a set of states (ie. the union of all those states reachable by a transition on the current symbol). Thus these states will be combined into a single DFA state.
Ni is a state from the source NFA
? is a finite set of symbols, that we will call the alphabet of the language the automaton accepts
Move( Si , a ) is the set of states reachable from Si by a. This function takes a state and a character, and returns the set of states reachable by one transition on this character.
e-closure( Si ) is the set of states reachable from Si by e . This function takes a state and returns the set of states reachable from it based on (one or more) e-transitions. Note that this will always include the state tself. We should be able to get from a state to any state in its e-closure without consuming any input.
Start state derived from S0 of the NFA
Take e-closure(S0)
Take the image of S0, Move(S0, ?) for each ? ? S, and take its e-closure
Iterate until no more states are added
S0 := e-closure({N0})
S := { S0 }
W := { S0 }
while ( W != Ø )
select and remove s from W
for each ? ?S
t := e-closure(Move( s,? ))
T[ s , ? ] := t
if ( t not in S ) then
add t to S
add t to W
Output is a set of states S and a set of transitions T.
Worst case is an exponential increase in the number of states and transitions.
A list of conventional algorithms.
Ted Leslie, Efficient Approaches to Subset Construction, masters thesis, Computer Science, University of Waterloo, 1995.[bibtex]
J. Howard Johnson and Derick Wood, Instruction Computation in Subset Construction, in Automata Implementation, Darrell Raymond and Derick Wood and Sheng Yu (eds.), Lecture Notes in Computer Science 1260, pp. 64-71, Springer Verlag, 1997.[bibtex]
Gertjan van Noord, The Treatment of Epsilon Moves in Subset Construction, Computational Linguistics, 26(1), pp. 61-76, April 2000. Available from www.let.rug.nl/~vannoord/papers/[bibtex]
Mehryar Mohri, Finite-State Transducers in Language and Speech Processing, Computational Linguistics, 23(2), pp. 269-311, June 1997.[bibtex]
Mehryar Mohri, On some applications of finite-state automata theory to natural language processing, Natural Language Engineering, vol. 2, pp. 61-80, 1996. Originally appeared in 1994 as Technical Report, institut Gaspard Monge, Paris.[bibtex]
Mehryar Mohri and Fernando C.N. Pereira and Michael Riley, A Rational Design for a Weighted Finite-State Transducer Library, Automata Implementation. Second International Workshop on Implementing Automata, WIA ’97, Lecture Notes in Computer Science 1436, Springer Verlag, 1998.[bibtex]
Emmanuel Roche and Yves Schabes, Deterministic Part-of-Speech Tagging with Finite-State Transducers, Computational Linguistics, 21(2), pp. 227-253, June, 1995.[bibtex]
Step 4) Systematicaly Shrink The DFA (Minimisatiion)
A list of conventional algorithms.
The fastest (O(|Q|log|Q|), where |Q| is the number of states) minimization algorithm (by John E. Hopcroft) is described in:
John E. Hopcroft, An n log n algorithm for minimizing the states in a finite automaton, in The Theory of Machines and Computations, Z. Kohavi (ed.), pp. 189-196, Academic Press, 1971.[bibtex]
David Gries, Describing an Algorithm by Hopcroft, Acta Informatica, vol. 2, pp. 97-109, 1973.[bibtex]
A. V. Aho, J. E. Hopcroft and J. D. Ullman, The Design and Analysis of Computer Algorithms, Addison-Wesley Publishing Company, 1974.[bibtex]
The third item on the list (i.e. the book) is probably the easiest to find, but beware that the description is somewhat hidden. Look for “partitioning”. The problem of minimizing states in the set of states of an automaton is equivalent to finding the coarsest partition of the set of states, consistent with the initial partition into final and non-final states, such that if states s and t are in one block of the partition, then states delta(s, a) and delta(t, a) are also in one block of the partition for each input symbol a.
An algorithm that is considered by some people to be equally fast for frequently encountered data is Brzozowski’s algorithm. It minimizes an automaton by performing reversal and determinization twice. The subset construction (determinization) is O(2|Q|), where Q is a set of states, but it depends on input (see master thesis by Ted Leslie in the Determinization section). The second paper here describes complexity of operations needed to implement Brzozowski’s algorithm.
J. A. Brzozowski, Canonical regular expressions and minimal state graphs for definite events, in Mathematical Theory of Automata, Volume 12 of MRI Symposia Series, pp. 529-561, Polytechnic Press, Polytechnic Institute of Brooklyn, N.Y., 1962.[bibtex]
C. Câmpeanu, K. Culik II, and Sheng Yu, State Complexity of Basic Oprations on Finite Languages, utomata Implementation. Proceedings of 4th International Workshop on Implementing Automata, WIA’99, Oliver Boldt and Helmut Jürgensen (Eds.), Postdam, Germany, LNCS 2214, Springer, 2001.[bibtex]
The following algorithm is different from all others because partial results can be used. It tests pairs of states for equivalence. The first paper describes a version with exponential time complexity. The second paper adds modifications that make it almost O(|Q|2).
Bruce W. Watson, An incremental DFA minimization algorithm, Finite State Methods in Natural Language Processing 2001, ESSLLI Workshop, August 20-24, Helsinki, Finland, 2001.[bibtex]
Bruce B. Watson, Jan Daciuk, An efficient incremental DFA minimization algorithm, Natural Language Engineering, Volume 9, Issue 01, March 2003. [bibtex]
The Hopcroft-Ullman is one of the best known. Its complexity is O(|Q|2), and it also requires O(|Q|2) memory, so it does not seem to be suitable for large automata. Pairs of states are considered, and the automaton has to be complete (i.e. it must have a sink, or dead state). A pair of states is distinguished if one of the states in the pair is final, and the other non-final. A pair of states is also distinguished if transitions labeled with the same symbol lead to another pair of states that was found distinguishable. For each pair of states, a list of pairs is found that are targets of transitions. Initially, pairs containing one final, and one non-final state are marked as distinguishable. Then all pairs that are on lists associated with those pairs are marked, and so on until no new pairs are marked. Pairs that are not marked are equivalent.
John E. Hopcroft and Jefferey D. Ullman, Introduction to Automata Theory, Languages, and Computation, Adison-Wesley Publishing Company, Reading, Massachusets, USA, 1979.[bibtex]
The Aho-Sethi-Ullman algorithm has the same complexity as the Hopcroft-Ullman algorithm, i.e. O(|Q|2), but it needs only O(|Q|) memory. As in the Hopcroft algorithm, the set of states is partitioned, and the blocks are refined in each step, until no more divisions occur. Two states are put into different blocks if they have transitions leading to states in different partitions. In difference to the Hopcroft algorithm, forward transitions are used for that purpose (the Hopcroft algorithm uses back transitions to split blocks with transitions leading to the current block).
Alfred V. Aho and Ravi Sethi and Jeffrey D. Ullman, Compilers. Principles, Techniques and Tools, Addison Wesley, 1986.[bibtex]
For acyclic automata, there are better methods than those given above. The minimization part of incremental and semi-incremental construction algorithms can be used.
Transducers
Mehryar Mohri, Compact Representations by Finite-State Transducers, ACL’94, Morgan Kaufmann, San Francisco, California, USA, 1994.[bibtex]
Step 5) Generate Code
Trivial Exercise

Hi, Was just wondering what software you use to create your very pretty NFA diagrams? At the moment I’m using JFLAP but it’s not very flexible when it comes to making them pretty. Many Thanks 😀
You might find the following interesting: <a href="http://lambda-the-ultimate.org/node/2293" title="Derivatives of Regular Expressions">Derivatives of Regular Expressions</a>.